1. Masking
- 데이터마스킹(개인정보로 민감한 데이터를 숨기는 것)과는 다른 내용
- 특정열에 어떤 값을 변경하고자 할 때 사용
- 판단의 기준이 DataFrame, 다시 말해 df[ ] 내부에 df[ ] 구조가 있는 것이라 생각하면 된다.
- 아래 예시를 통해, 검거율 100% 이상이였던 값들이 100으로 변경된 것을 확인할 수 있다.
gu_df[ gu_df[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']] > 100 ] = 100
gu_df.tail(10)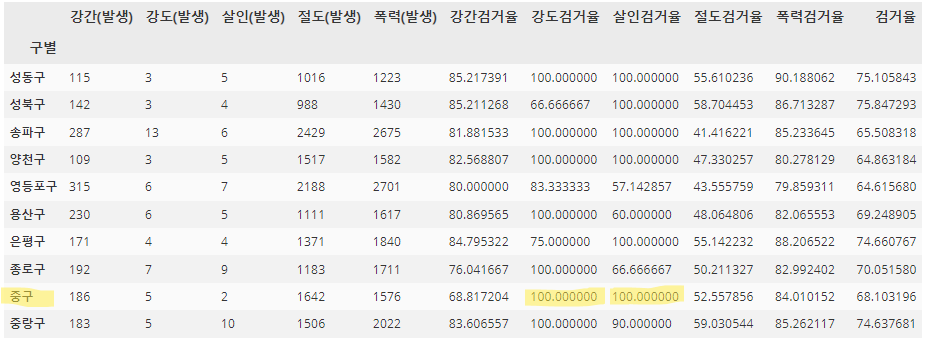
- 조금 더 나아가서, 똑같은 조건을 Masking을 쓰지 않고 코드를 작성해보면, 아래와 같이 작성된다.
columns = ['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']
gu_df_rate = gu_df[columns]
# iterrows() : iterable을 행이름, 행 단위로 하나씩 꺼내주는 함수
for row_index, row in gu_df_rate.iterrows():
for column in columns:
if row[column] > 100:
# at[ ] : 행, 열 directly 가리킬 수 있는 함수
gu_df.at[row_index, column] = 100
gu_df.tail(10)
위의 코드에서 눈여겨 봐야할 함수는 iterrows와 at이다.
1) iterrows()
- DataFrame.iterrows()
- 각 행의 이름과 행을 출력해준다.
- 아래와 같이 row_index가 행의 이름, row가 행임을 확인할 수 있으며, 두 개의 인자가 아닌 하나의 인자로 받을 때는 tuple로 출력된다.

2) at[ ]
(출처: https://kongdols-room.tistory.com/117)
- 패스트 인덱싱 메소드 중 하나
- 하나의 스칼라 값에 접근하는 데 특화되어 있으며, Series와 DataFrame에서 모두 사용 가능하다.
- 다수의 행/열에 접근할 수 있는 df.loc[ ]와 달리, df.at[ ]는 하나의 값에만 접근 가능하다는 것이다
- loc과 동일하게 label 기준으로 데이터에 접근한다.
# Series에서의 사용
Series.at['index_label']
# DataFrame에서의 사용
DataFrame.at['index_label', 'column_label']
2. Filtering
- 특정 행/열을 꺼내고자 할 때 사용
- Masking과 달리, 판단의 기준이 Series
- 다시 말해, df[ ] 내부에 Series가 있는 것이라 생각하면 된다.
- 필터링에서 논리 연산자는 and, or, not 대신 "&", "|", "~"을 사용한다.
gu_df[ gu_df['살인(발생)'] == 0 ]
# and
gu_df[ (gu_df['살인(발생)'] > 7) & (gu_df['폭력(발생)'] > 2000) ]
# or
gu_df[ (gu_df['살인(발생)'] > 7) | (gu_df['폭력(발생)'] > 2000) ]
# not
gu_df[ ~ (gu_df['살인(발생)'] > 5) ]
- 에러 :
The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
필터링에서 1) 잘못된 논리 연산자를 사용하거나, 2) 두 개 이상의 조건을 적을 때 ( )로 범위를 지정해 주지 않는다면 위의 에러가 발생하게 된다.
'멋쟁이 사자처럼 AI SCHOOL 5기 > Today I Learned' 카테고리의 다른 글
| [2주차 총정리] Feature Scaling (Feature Normalization) 이론 (0) | 2022.03.23 |
|---|---|
| [2주차 총정리] 데이터프레임 합치는 방법 (join, merge, concat) (0) | 2022.03.23 |
| [2주차 총정리] pandas 유용한 함수 (apply, lambda, map 함수) 총정리 (0) | 2022.03.22 |
| [2주차 총정리] pd.DataFrame 기초 함수, hist 함수, pivot_table, 결측값 처리 방법 (0) | 2022.03.22 |
| [2주차 총정리] Python 초보자를 위한 class 기초 총정리 (0) | 2022.03.22 |
