import sqlite3
dbpath = "chinook.db"
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
"""전반적인 흐름
# 1. script 만들고
script = '''
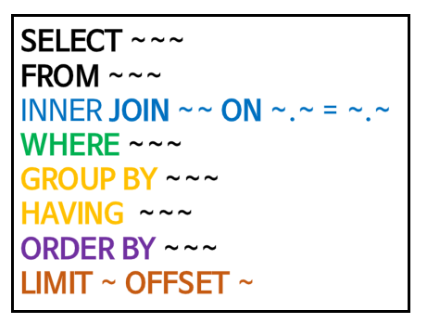
SELECT ~~~
FROM ~~~
INNER JOIN ~~
ON ~.~ = ~.~
WHERE ~~~
GROUP BY ~~~
HAVING ~~~
ORDER BY ~~~
LIMIT ~ OFFSET ~
'''
# 2. sql_query로 데이터프레임 형식으로 읽고
df = pd.read_sql_query(script, conn)
df.head(10)
# 3. 작업 완료 후 연결 끊기
conn.close()
"""
# NULL
# - 모두 다른 unique한 값으로 자동 인식
# - 무엇보다도 작은 값
1. Sorting (ORDER BY)
script = """
SELECT
name,
milliseconds,
albumid
FROM
tracks
ORDER BY
albumid ASC, -- 1순위 조건
milliseconds DESC; -- 2순위 조건
"""
df = pd.read_sql_query(script, conn)
df.head()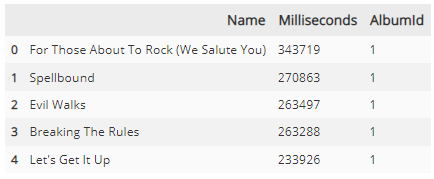
2. Filtering (DISTINCT, WHERE+LIKE/IN/LIMIT/BETWEEN/IS NULL)
1) DISTINCT
# 예시1
script = """
SELECT
DISTINCT city -- (distinct : 뚜렷이 구별되는, 별개의) 중복되지 않는 값들만 꺼내줘
FROM
customers
ORDER BY
city;
"""
# 예시2
script = """
SELECT
DISTINCT city, country -- city & country [ 2개의 열의 값이 모두 동일한 행 ]들의 경우 중복 제외
FROM
customers
ORDER BY
country;
"""
2) WHERE+LIKE/IN/LIMIT/BETWEEN/IS NULL
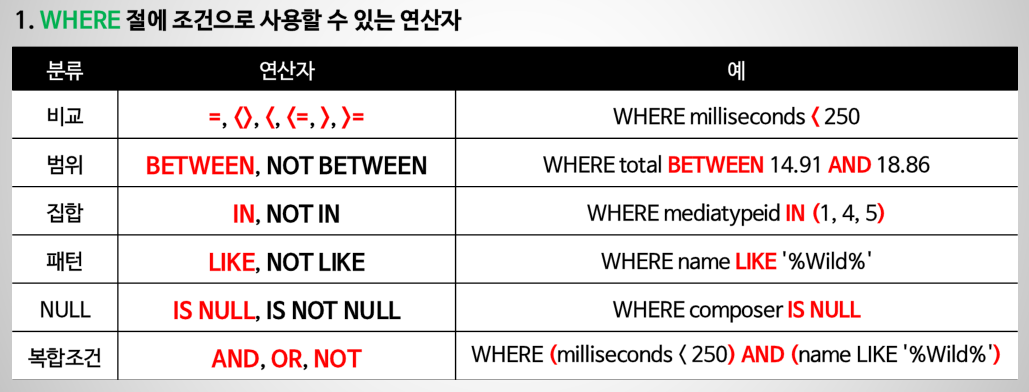
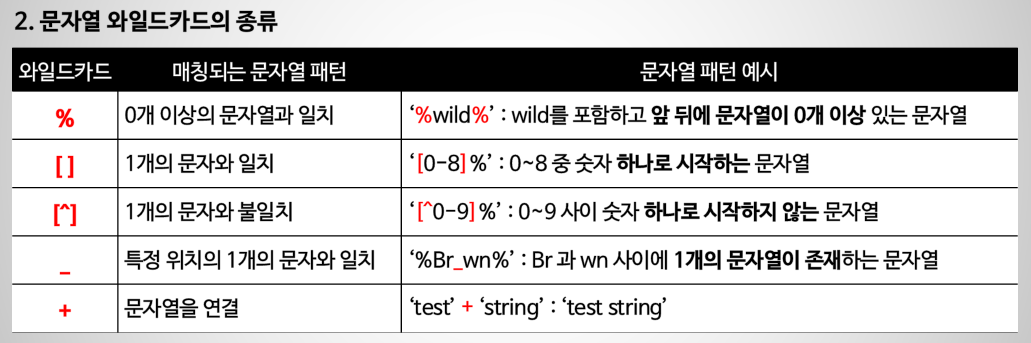
WHERE column_1 = 100;
WHERE column_2 IN (1,2,3);
WHERE column_3 LIKE 'An%';
WHERE column_4 BETWEEN 10 AND 20;
# OR
script = """
SELECT
TrackId,
Name,
MediaTypeId
FROM
Tracks
WHERE
(MediaTypeId = 1) OR (MediaTypeId = 2);
-- MediaTypeID IN (1,2) 과 같은 결과
"""
# LIKE
script = """
SELECT
trackid,
name
FROM
tracks
WHERE
name LIKE '%Br_wn%';
"""
# NOT IN
script = """
SELECT
name,
albumid,
mediatypeid
FROM
tracks
WHERE
mediatypeid NOT IN (4, 5);
"""
# LIMIT ~ OFFSERT ~
script = """
SELECT
trackid,
name,
milliseconds
FROM
tracks
ORDER BY
milliseconds DESC
LIMIT 1 OFFSET 1;
"""
# IS (NOT) NULL
script = """
SELECT
Name,
Composer
FROM
tracks
WHERE
Composer IS NOT NULL
ORDER BY
Name;
"""
3) Joining (JOIN & ON)
3.1 INNER JOIN
SELECT m, A.F, B.f, n
FROM A
INNER JOIN B ON B.f = A.f
script = """
SELECT
trackid,
tracks.name as track, -- AS 를 통해 alias를 만들어줄 수 있습니다. (아래 실행 결과를 참고)
albums.title as album,
artists.name as artist
artists.artistid AS artistID
FROM
tracks
INNER JOIN albums ON albums.albumid = tracks.albumid -- from A inner join B on A.x1 = B.x2
INNER JOIN artists ON artists.artistid = albums.artistid
-- INNER JOIN artists USING(ArtistID)와 동일
WHERE
artists.artistid = 10;
"""
3.2 LEFT JOIN
SELECT m, A.F, B.f, n
FROM A
LEFT JOIN B ON B.f = A.f
script = """
SELECT
Name, -- <- artists (A)
Title -- <- albums (B)
FROM
artists
LEFT JOIN albums ON artists.ArtistId = albums.ArtistId
WHERE Title IS NULL -- A 기준으로 join했기에 Title 열이 NULL일 수 있음
ORDER BY Name;
"""
3.3 Self JOIN
script = """
SELECT * FROM employees
LIMIT 3;
"""
df = pd.read_sql_query(script, conn)
df.head()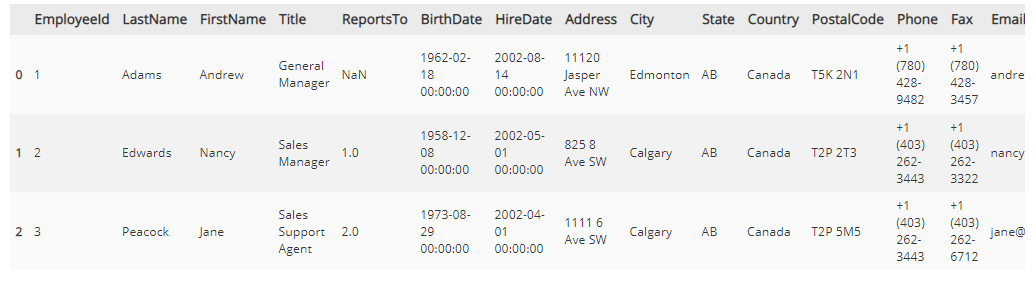
script = """
SELECT m.firstname || ' ' || m.lastname AS 'Manager',
e.firstname || ' ' || e.lastname AS 'Receives reports from'
FROM
employees e
INNER JOIN
employees m
ON
m.employeeid = e.reportsto -- 테이블 employees의 복제본이 존재한다고 상상하고 2개의 동일한 테이블을 서로 JOIN 한다고 이해
ORDER BY
manager;
"""
df = pd.read_sql_query(script, conn)
df.head()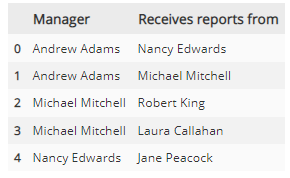
4) Grouping (GROUP BY & HAVING)

# 예시1
script = """
SELECT
tracks.albumid,
title,
COUNT(trackid)
FROM
tracks
INNER JOIN albums ON albums.albumid = tracks.albumid
GROUP BY
tracks.albumid
HAVING
COUNT(trackid) > 15;
"""
# 예시2
script = """
-- 주문일자(InvoiceDate)에서 년도 값을 뽑아내어 해당 년도에 발생한 주문(InvoiceId)의 수량을 확인
SELECT
STRFTIME('%Y', InvoiceDate) AS InvoiceYear, -- STRing-Format TIME & 4글자 년도값은 '%Y' (포맷 참고 @ https://bit.ly/32BNyhd)
COUNT(InvoiceId) AS InvoiceCount -- 해당 년도에 발생한 주문(InvoiceId)의 총 수량(COUNT)
FROM
invoices
GROUP BY
STRFTIME('%Y', InvoiceDate)
-- 주문일자(InvoiceDate)의 년도 값을 기준으로 그룹화
ORDER BY
InvoiceYear;
"""
5) SubQuery
# 코드1
script = """
SELECT * FROM albums
WHERE artistid = 12;
"""
# 코드2
script = """
SELECT * FROM tracks
WHERE albumid IN (16, 17);
"""
# 코드1 + 코드2
# Tracks에 있는 곡(행)들 중,
# Track(곡)이 속한 Album에서의 ArtistID가 12인 곡(행)들을 꺼내고 싶음
# -> Tracks에 있는 곡들 중 Artist가 Black_Sabbath인 곡들을 추려내고 싶다
script = """
SELECT
TrackId,
Name,
AlbumId
FROM
Tracks
WHERE
AlbumId IN ( -- Albums 테이블에서 ArtistId 열의 값이 12인 행들의 AlbumId 열의 값들 <- 이 AlbumId 값들이 타겟 그룹이 됨
SELECT
AlbumID
FROM
Albums
WHERE
ArtistID = 12
);
"""
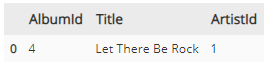
- 다른 예시로 더 자세하게 보면,
# 코드1
script = """
SELECT * FROM albums
WHERE title = 'Let There Be Rock'; -- 앨범의 제목
"""
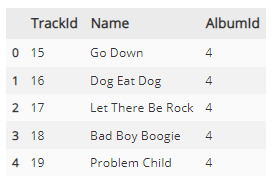
# 코드2
script = """
-- Let There Be Rock 라는 제목을 가진 앨범의 수록곡을 모두 확인하고자
SELECT trackid,
name,
albumid
FROM tracks
WHERE albumid = 4;
"""
# 코드1 + 코드2
script = """
SELECT trackid,
name,
albumid
FROM tracks
WHERE albumid = ( -- 우리가 Let There Be Rock 라는 제목을 가진 앨범의 아이디 값을 알지 못한다면?
SELECT albumid
FROM albums
WHERE title = 'Let There Be Rock'
);
"""
df = pd.read_sql_query(script, conn)
df.head()
- 집계함수를 두 번 적용하고 싶을 때에도 SubQuery를 사용할 수 있다.
# 에러 발생 코드:
script = """
SELECT AVG(SUM(bytes)) -- SELECT 문에서 집계함수의 결과 값에 바로 중첩하여 집계함수를 적용할 수 없습니다.
FROM tracks
GROUP BY albumid;
"""# 1. 먼저, SIZE 열 만들어놓고
script = """
SELECT
SUM(bytes) AS SIZE
FROM
tracks
GROUP BY
albumid;
"""
# 2. SIZE를 AVG 함수로 집계
script = """
SELECT
AVG(SIZE)
FROM
(SELECT
SUM(bytes) AS SIZE
FROM
tracks
GROUP BY
albumid);
"""'멋쟁이 사자처럼 AI SCHOOL 5기 > Today I Learned' 카테고리의 다른 글
| [5주차 총정리] scikit-learn 머신러닝 모델 학습 단계 Framework (0) | 2022.04.12 |
|---|---|
| [4주차 총정리] Python 기반 SQL 프로그래밍(6) _Selenium+SQLite 실습 (0) | 2022.04.11 |
| [4주차 총정리] Python 기반 SQL 프로그래밍(4) _DML 실습 (0) | 2022.04.08 |
| [4주차 총정리] Python 기반 SQL 프로그래밍(3) _DDL 실습 (0) | 2022.04.08 |
| [4주차 총정리] Python 기반 SQL 프로그래밍(2) _SQL 입문자를 위한 기초실습 (0) | 2022.04.08 |
